
Overview The #PhotoMappers project is in its 11th year of providing situational awareness to federal,…
We received a request from Humanitarian OpenStreetMap (HOT) shortly after super storm Sandy hit the northeastern US in October/November 2012. They were interested in deploying the “expert” crowd (GISCorps volunteers) on a crowdsourcing project that they launched shortly after the storm. They asked that the GISCorps volunteers help evaluate the crowd’s overall accuracy, by rating a sample of the site’s images using the same interface. Volunteers came from seven countries: Amelia Ley (US), Naiara Fernandez (Spain), Roxroy Bollers (Guyana), Giedrius Kaveckis, (Italy), Jeffrey Pires, (US), David Anderson (US), Meliv Purzuelo (Philippines), Kevin Pomaski (US), and Eyob Teshome (Ethiopia). The following report describes the details of the project.
Aerial Damage Assessment Following Hurricane Sandy
Jennifer Chan, Harvard Humanitarian Initiative & Northwestern University
John Crowley, Harvard Humanitarian Initiative and Humanitarian OpenStreetMap
Shoreh Elhami, GISCorps Founder
Schuyler Erle, Idibon and Humanitarian OpenStreetMap
Robert Munro, Idibon
Tyler Schnoebelen, Idibon
May 2013
Executive Summary
This document is an after-action report for information processing following Hurricane Sandy, one of the largest disasters to hit urban areas in the past 12 months. We analyze the aerial damage assessment process in a number of ways, reporting the results and suggesting methods to ensure quality and reliability for similar responses to future events.

Introduction
Following Hurricane Sandy’s landfall on the Eastern seaboard of the USA in 2012, the Civil Air Patrol (CAP) took over 35,000 GPS-tagged images of damage-affected areas. This was performed as part of their mandate to provide aerial photographs for disaster assessment and response agencies, primarily FEMA, who used the aggregate geolocated data for situational awareness.
The scale of the destruction meant that there was a relatively large amount of photographs for a single disaster. As a result, it was the first time that CAP and FEMA used distributed third-party information processing for the damage assessment, with 6,717 public, non-expert volunteers evaluating the level of damage present in the images via an online crowdsourcing system. The contributors viewed one image at a time and gave a three-way judgment: little/no damage; medium damage; or heavy damage. This report is quality of the damage assessment evaluating the volunteer workers’ performance in three ways:
1. Inter-annotator agreement: how often did volunteers agree with each other?
2. Comparison with experts: 11 expert raters from the GISCorps assessed a selection of the images as part of this report (also as volunteers).
3. Ground-truthed ratings: comparison to ratings made by FEMA at the same grid locations.
Additionally, this report evaluates the GISCorps’ volunteer experience to understand motivating factors for skilled volunteer engagement and to learn how to improve crowdsourcing platforms and process for future disaster deployments.

Deployment and Author Involvement
The volunteers used the MapMill software (Warren, 2010), released by the Public Laboratory for Open Technology and Science (PLOTS) and adapted for this task by Humanitarian OpenStreetMap. It was deployed and run by Schuyler Erle (author). The platform was developed at Camp Roberts RELIEF, organized by John Crowley (author), in collaboration with the Civil Air Patrol, FEMA and professionals including Robert Munro (author). Erle’s involvement and subsequent analysis was supported by Idibon staff including Tyler Schnoebelen (author), and the GISCorps volunteers were managed by Shoreh Elhami (author). Jennifer Chan (author) supported both the deployment and analysis.
Agreement among non-experts
Inter-annotator agreement is a common metric for evaluating accuracy in crowdsourced tasks when the “correct” answer is not known. If there is a large amount of agreement about a judgment from multiple crowdsourced workers, then chances are that the shared judgment is the correct one. The public, non-expert volunteers rated a total of 35,535 images—these received, on average, 4.51 ratings each. We restrict the analysis to the 17,070 images that had 3 or more ratings.
As Figure 1 demonstrates, there is a high level of agreement. The public volunteers had majority agreement on 15,968 images (93.54%). And even if we restrict ourselves to a “super-majority” definition of agreement, agreement was still at 80%. That said, there was unanimous agreement on less than 50% of the images, showing that complete agreement was relatively rare.
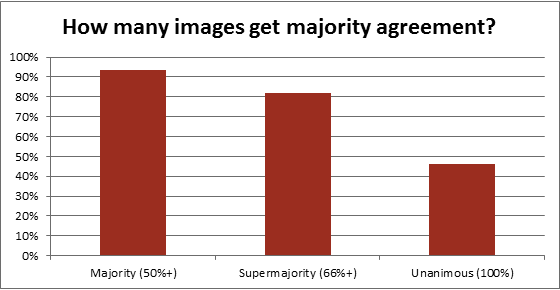
Figure 1: Three different levels of quality assessment on 17,070 images (limited to images with three or more ratings per image), showing that non-expert volunteers generally agreed with each other on how to classify an image.
The fact that there is a consensus for most images is encouraging. But how high is the quality of the actual raters? For the evaluation, we defined someone as a Good Rater if their own ratings correspond to majority opinions.[1] There are 6,717 public volunteers, they give ratings to an average of 23.86 images (median of 5). There are 34,433 images that have majority agreement. How do the non-expert volunteers do on these?
There are 4,370 non-expert volunteers that we have enough data to evaluate (i.e., they have 3+ ratings for images where there are majority verdicts). It turns out that most of the volunteers agree with each other. The chart below shows how, for example, 3,652 of the 4,370 users agree with the majority verdict for the majority of images that they rate (83.57%).

Figure 2: Focusing on raters, we see that most non-expert raters are consistent with the majority opinions.
Expert ratings
For the comparison with experts, 720 of the most problematic images were assessed by 11 GISCorps experts, using the same platform and instruction set. We defined the “tough” images as those with the least agreement between the annotators. The average number of experts/image was 3.18 (median of 3). (The average number of public volunteer judgments for these tough images was 15.6, median of 14).
How much agreement did experts have on these tough cases? In Figure 3, we show that experts generally agree about how to rate tough images unless we hold them to an unrealistic expectation of perfect agreement.[2] 81% of the images had a supermajority agreement among the experts, compared to just 37% for public volunteers, showing that the volunteers were not as accurate (in terms of inter-annotator agreement) for these images.[3]
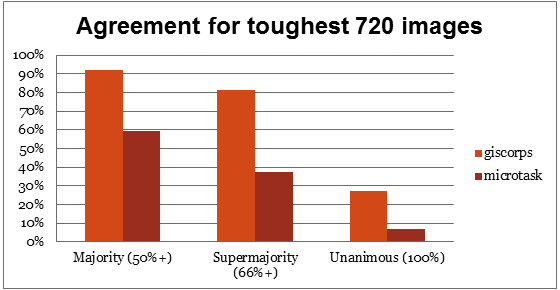
Figure 3: Tough-to-classify images rated by experts received pretty consistent ratings; note that these images were chosen *because* non-experts had a lot of disagreement.
In the tough images, both experts and public volunteers are giving out the same proportions of ratings.

Figure 4: Raters generally gave out the same kinds of ratings.
The main area of disagreement between the groups were for images that the volunteers said showed no real damage and which the experts said showed some damage (9% of the images). As Table 1 shows, only 11% of the ratings were dramatically off (where one group said there was no damage and the other group said there was severe damage). 63% of the toughest images were agreed upon between experts and non-experts.

Table 1: Rating distributions for the 662 tough images that have majority votes among both groups (i.e., there are 30 images that a majority of experts call “0” but which a majority of public volunteers call “5”).
The truth on the ground
The third evaluation produced a negative result, as we were not able to find a strong correlation between the aerial evaluations and FEMA’s ground-reports. We can identify some grids where this is due to timing: the presence of flood-water was typically marked as high damage, but it had receded before the FEMA assessments (the initial aerial assessments were completed in the first days for immediate resource allocation, insurance assessments, etc., while the ground reports were for more details and pin-pointed exercise.) In other places, there was a mismatch between aerial photographs and grid-references. For example, while CAP ratings applied to a large area, only a small subsection of that would need to be affected for FEMA to call it damaged.
In general, the largest agreement is with mutual 0’s, where there is essentially no damage. This also is true when we look at how the “everyone agrees” patterns with FEMA’s classifications from on-the-ground. The next table also demonstrates that the highest damage ratings from the aerial photographs are only rated as “affected” by people on the ground.

Table 2: Images per FEMA category; ratings are those that both experts and public volunteers agree upon.
In fact, none of the images that are ranked as “Destroyed” by FEMA got consistent high-ratings from raters (neither experts nor non-experts).
There are no previous reports comparing damage assessment from CAP imagery and FEMA ground-truth reports (that we are aware of), so this disparity may not be specific to the context of a crowdsourced workforce. We conclude that the rating systems need to be investigated in more detail and that different correlation/aggregation methods should be tested to ensure compatibility between the assessment methods.
Improving the platform
In this section, we review findings from interviews with the GISCorps volunteers after the project was completed. These interviews explain motivations for these volunteers as well as which aspects of the project should be kept and which should be adjusted.
All GISCorps volunteers who agreed to participate in the project were contacted via email as asked to participate in a semi-structured 30-minute phone interview. Nine volunteers responded and the interviews were completed via telephone and/or Skype between November 28th and November 30th, 2012. One member of the research team coded and analyzed the interviews in terms of the following themes:
- GIS volunteer skills & background, including prior experience in a disaster context
- User experience with the platform
- Communication & feedback
- Volunteer engagement & sustainability
- Volunteer recommendations
Additional coding was again performed to identify themes that emerged across interview questions as well as issues and topics that emerged across individual interviews.
GIS volunteers skills and backgrounds
As anticipated, almost all of the GISCorps volunteers described themselves as GIS specialists. Five of them of them were practitioners in organizations including for-profit companies and non-governmental organizations (NGOs). There were three researchers with graduate level training employed in research institutions in Germany, Ethiopia and Spain. Four volunteers, based in the United States focused solely on the US context. The remaining five members worked in Guyana, Ethiopia, Spain, the Philippines, and Germany.
Only one GISCorps volunteer both worked and lived in the regions affected by SuperStorm Sandy. This member not only grew up in the New Jersey region, but also currently worked for National Grid, which was directly involved in restoring power and electricity in the region. The other volunteer members did not have prior experiences as traditional disaster responders. The also had no prior working experience with disaster response organizations. Two members reported previous experience working as digital volunteers, one who helped process 2010 Haiti Earthquake imagery and the other with experience analyzing imagery after Hurricane Katrina.
User experiences with the platform
Overall, the volunteers’ experience with the Sandy MapMill platform was very positive. As a group they felt the platform was “streamlined”, “easy to use”, and “simple.” One member felt that the platform was so well designed that it “could be used by people with no technical background.”
Instructions
Volunteers frequently used the instructions describing them as clear and easy to understand. The instruction page interface was intuitive and many volunteers found it easy to review the instructions when needed. Others felt that the instructions on ‘light’, ‘moderate’ and ‘heavy’ categorizations were limited, especially for “blurry” or “unreadable” images (see categorization and recommended next steps).
Image types and quality
Some volunteers felt that they assessed the same images more than once. Others noted variations in the image quality. They recalled images which covered large geographic areas and felt it became difficult to identify damaged structures. Other images were “too blurry” or “completely black”. For uninterpretable images, some volunteers clicked ‘heavy’ to proceed to the next image, while others clicked ‘moderate’ and ‘light’ to proceed. One volunteer received a “black image” as his first image during this volunteer experience and assumed that this reflected an error in the MapMill platform design or web browser. He spent approximately 30 minutes accessing the website from different browsers as well as trying to contact the project facilitator with no response. In the end, he clicked ‘light’ and realized it was the image and not the platform.
Imagery magnifying glass
Volunteers appreciated the magnifying glass and many felt that it aided in identifying damaged structures which helped them better categorize images. According to some volunteers, at times the magnifying glass was not functional. Lastly one volunteer noted that the magnifying glass was very helpful because he was using a computer with a small screen.
Workflow
Overall the volunteers found the workflow smooth, but many noted duplicate images. Three volunteers—one residing in the remote Italian mountains, another in Ethiopia and the third in Philippines—noted bandwidth variations that intermittently affected their workflows. None of these volunteers described bandwidth as prohibitive to completing the project. Of note, it is unknown if the GIS Volunteer from Nigeria experienced bandwidth difficulties because he did not respond to the interview request.
Categorizing images
Many volunteers described the categorization process as okay, and reported greater ease in assigning ‘heavy’ and ‘light’. Differentiating between ‘moderate’ and ‘light’ or ‘moderate’ and ‘heavy’ was more difficult, particularly for blurry images and images with flooding. One volunteer described being unable to determine flood depth or impassable paths and that contributed to uncertainty in category assignment.
Volunteers shared different methods which they used to assess imagery and assign categories. One volunteer first assessed for heavy damage and then chose between light and moderate. Others closely assessed roads, homes, and degree of flooding. When objects within the image were “out of its place”, “completely unusable” or “irregular” this was deemed ‘heavy’ by other volunteers.
Communication and feedback
Most volunteers felt that a communication platform where they could ask questions would be helpful for future projects. One volunteer felt that this may improve the categorization process and another volunteer believed that project objectives and instructions could be reiterated in this environment. Two volunteers would have liked immediate feedback during the project. One recommended that there be real-time feedback to volunteers about the quality of their assessments. This feedback was described as performance statistics including time spent on images and volunteer assessment comparisons. He suggested that this could be automated on the platform and/or be included in online discussions with project coordinators. Another respondent with an operational NGO background also recommended immediate feedback, but noted that the capacity needed to achieve this would be challenging.
Volunteer engagement and sustainability
The most common reason why GISCorps members volunteered for this project was because they “wanting to give back” and “help”. Some volunteers want to “give back” with their GIS knowledge and skills. Others expressed interest in learning more about the practical applications of GIS and crowdsourcing in the disaster context.
In general, all nine interviewed volunteers were willing to volunteer in the future, if called to action. Their anticipated volunteer commitments varied both by their perceptions of disaster needs, degree of feedback during the project and deployment duration. Some volunteers described being willing to help for 30 minutes to 4 hours each day, while others anticipated their commitment in weekly time intervals that ranged from one hour to five hours each week.
Discussion
Many of the themes that emerged in the interviews with experts are likely to be useful to non-experts, as well—that is, removing or clarifying what to do with blurry images is useful for anyone. In this discussion section, we return to the question of whether non-experts could be used for disaster image assessment, which is increasingly important question since experts are a scarce resource (Crowley and Jennifer Chan, 2011).
In general, a volunteer’s inter-annotator agreement goes up the more experience they have with the task. Experience is, after all, what makes someone an expert. But this is true even of non-expert volunteers. Using overall agreement per worker, there is 95% confidence on an image’s rating once five workers have seen it:

Figure 5: The more workers assess an image, the more confident we can be about the assessment. If you have experienced crowdsource workers available (the lighter, upper line), fewer raters are required.
Depending on the quality of assessment required, you would choose between four and six and judgments to ensure accuracy, and increase the number of judgments where disagreement occurs, or back off to experts.
Most disasters are not as prominent as Sandy and might struggle to find a large enough volunteer community. While there were a large number of volunteers, there was a power-law distribution, where majority of the work was completed by a minority of the volunteers, with that minority having a stronger personal tie to the project or to the region. Further, there was a sharp drop-off in volunteer engagement after the first few days, with volunteers not being able to complete all the judgments of images taken in the later part of the recovery. The recruitment of volunteers through social media was successful, but it did not produce a sustainable volunteer effort. We cannot definitively conclude that crowdsourcing the callout for volunteers produced more workers than reaching out through private networks, but it was certainly the easiest option to find people quickly at launch. In previous volunteer crowdsourcing efforts, there is evidence that recruiting people privately through strong social ties lead to more committed workforces (Munro, 2013). A smaller recruitment process would also produce a team that was easier to manage, and also alleviate some of the security concerns in publicly distributing high-resolution images of potentially sensitive areas.
Crowdsourcing is typically paid, so we also surveyed 20 professional crowdsourced workers to establish a price-point for paid, crowdsourced damage assessment. The results varied from $0.001 to $0.02 per judgment depending on worker expertise. This would come to a maximum of US$3,000 for the entire operation if paid workers were used, which is less than the cost to manage volunteers and on par with a single aerial survey.
We conclude that it is possible to deploy the information processing strategies that we used for Hurricane Sandy aerial image assessment for future disasters, while also addressing some of the quality and reliability concerns that arise from using crowdsourced workforces.
Recommendations
- Hire non-expert microtaskers in order to process the majority of data, as discussed in the previous section.
- Plan on 4-6 non-expert judgments per image.
- Route difficult images to expert annotators (or a larger number of non-experts).
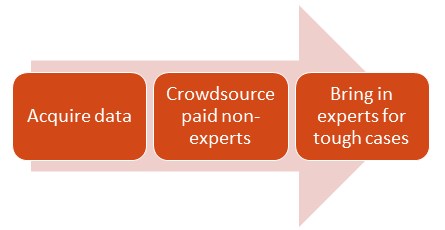
Figure 6: Recommended process
- Add instructions on how to interpret images and assign categories.
- Include options to decline image categorization (e.g., for dark or blurry images).
- Consider showing images within their geographical region and/or clustering images from the same region to be considered together.
- Consider showing pre- and post-disaster images for comparison purposes.
- Consider an initial step to filter out blank/black/otherwise uninterpretable images prior to the damage assessment task.
- Consider investing in the capacity to provide project coordinators who volunteer shifts to provide online support, feedback and other communications to assessors during a deployment.
- Determine better ways to map judgments of aerial data to the on-the-ground assessments that FEMA performs.
Future research directions
- Civil Air Patrol (CAP) assessment analysis: This study would evaluate the experiential expertise of CAP volunteers and their expert assessments compared to the crowd and to GIS remote sensing experts.
- Paid workforce analysis: This study would investigate the potential added value of incorporating paid work forces into future deployments. A comparative analysis of the inter-assessor agreement between paid workers, expert volunteers, and CAP volunteers. The study would also include a design simulation, where paid workforces would be positioned at different workflow stages along with the crowd and experts to determine the optimal use of this type of workforce and at what cost.
- Pre and post disaster imagery analysis: A feasibility to benefit study.
- Stage 1 – A feasibility study on acquiring pre-disaster imagery by CAP as a preparedness activity. The project would begin with selecting 3 US regions most at risk for future disasters. This pre-disaster or baseline imagery could be acquired from exiting databases or potentially investing in CAP fly-overs to acquire these imagery datasets. Determine the capacity, investment and time to order and process imagery and design a pre-post assessment platform.
- Stage 2- A pilot comparison study that analyzes the degree of improvement in pre-post imagery assessments, both by experts and the crowd. This study would also include a cost/benefit analysis for accuracy gained compared to the investment needed to acquire pre/post data as well as design the platform for this specific use.
- Imagery cluster analysis: This study would investigate the potential added value of clustering images for serial and parallel assessment by volunteers. This includes modeling imagery sets by various cluster geographical sizes, and the degree of cluster overlap between volunteers to potentially validate or increase inter-assessor agreement. It would also include a comparative analysis between the crowd, experts and CAP volunteers.
- Combining information from other sources: This would project look for ways to combine aerial analysis with information from official and citizen sources. For example, it might employing Natural Language Processing over social media (Munro, 2012), adding eye-level photographs from ground teams or affected populations, or potentially incorporating other types of crowdsourced information processing. This would allow responders to quickly link the damage assessments to ground-based reports at the same locations.
- Evaluate vehicle accessibility. Vehicular access is vital for disaster response (Dolinskaya et al. 2013) and the process used here could have as easily focused on blocked or damage roads.
- Simulate, learn, and iterate collaborative project: This cross-cutting collaborative project will interface with the above projects over years to integrate design, experimental and learning simulations to complement the above studies. Evaluation methods and designs will be employed to help facilitate learning from each project and translate this into future iterations for practical deployments as well as new areas of research and study.
References
Crowley, John, and Jennifer Chan. 2011. “DISASTER RELIEF 2.0: The Future of Information Sharing in Humanitarian Emergencies.” Harvard Humanitarian Initiative and UN Foundation-Vodafone Foundation-UNOCHA.
Dolinskaya, Irina, Karen Smilowitz, and Jennifer Chan. 2013. Integration of Real-Time Mapping Technology in Disaster Relief Distribution. Center for the Commercialization of Innovative Transportation Technology. Northwestern University.
Munro, Robert, Schuyler Erle and Tyler Schnoebelen. 2013. Analysis After Action Report for the Crowdsourced Aerial Imagery Assessment Following Hurricane Sandy. 10th International Conference on Information Systems for Crisis Response and Management. Baden Baden, Germany.
Munro, Robert. 2012. Crowdsourcing and Natural Language Processing for Humanitarian Response. Crisis Informatics and Analytics. Tulane.
Munro, Robert. 2013. Crowdsourcing and the Crisis-Affected Community: lessons learned and looking forward from Mission 4636. Journal of Information Retrieval 16(2). Springer.
Warren, Jeffrey Yoo. 2010. Grassroots mapping: tools for participatory and activist cartography. PhD dissertation. Massachusetts Institute of Technology.
Related Missions


